How to Read the AI Visibility Inspector: Complete Metric & Signal Guide

The AI Visibility Inspector provides a complete diagnostic view of how modern AI systems interpret, extract, and evaluate your content. This guide explains every metric inside the Inspector – what it measures, why it matters for AI retrieval, and how to improve your scores with practical, high‑impact actions.
AI systems don’t rank pages. They interpret structure, extract data, evaluate entities, assess schema, and decide whether your content is eligible to appear in AI‑generated answers. The Inspector translates these invisible signals into clear, actionable measurements across structure, extractability, schema, entity clarity, freshness, semantic coverage, and engine‑specific compatibility.
Use this guide as your reference when reviewing any Inspector report. Each section below corresponds to a specific part of the dashboard, with definitions, interpretation rules, and improvement steps for every metric.
AI Retrieval Index (Overall Score)

The AI Retrieval Index is the Inspector’s primary score – a single, unified measurement of how well your page can be interpreted, extracted, and cited by modern AI systems. It reflects the combined strength of your structural signals, semantic depth, schema clarity, entity stability, and freshness indicators.
A higher score means your content is easier for AI models to understand, more extractable, and more likely to appear in AI‑generated answers. The accompanying letter grade (A–D) provides a quick qualitative assessment of overall visibility strength.
The Index is supported by two foundational sub‑scores:
- Structure – how cleanly your page communicates hierarchy, chunking, headings, and layout signals.
- Depth – how comprehensively your content covers the topic, including semantic richness, topical completeness, and contextual clarity.
Together, these metrics show whether your page is both structurally sound and semantically substantial, the two core requirements for strong AI retrieval.
AI Assessment (Page Interpretation Summary)
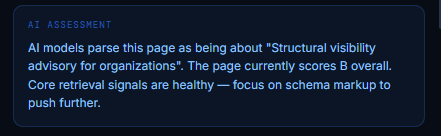
The AI Assessment shows how modern AI systems interpret the core meaning and purpose of your page. It extracts the dominant topic, identifies the primary intent, and summarizes how AI models classify the content before any scoring takes place. This interpretation is crucial: if AI systems misunderstand your page’s topic, every downstream retrieval signal becomes weaker.
The assessment also provides a quick diagnostic of your overall visibility health, including your current grade, and highlights the most impactful area to improve next. When the summary says “Core retrieval signals are healthy,” it means your structural, semantic, and schema foundations are strong enough for AI systems to understand the page reliably. When it recommends focusing on a specific area (such as schema markup), that is the highest‑leverage improvement for increasing AI retrieval probability.
This block helps you confirm that AI models are “reading” your page the way you intended, and alerts you when the interpreted topic drifts from your actual content goals.
Critical Actions (Immediate Fixes & Priority Signals)
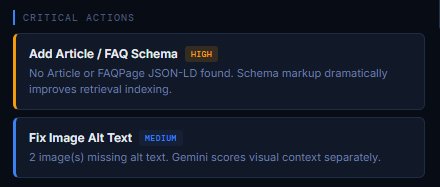
Critical Actions highlight the most impactful improvements you can make to strengthen your page’s AI visibility. These recommendations are prioritized by severity, High, Medium, or Low, based on how strongly each issue affects AI retrieval, schema clarity, extractability, and engine‑specific interpretation.
Each action is generated from real structural, semantic, and schema gaps detected on the page. High‑priority items typically relate to schema markup, structural clarity, missing metadata, or broken extractability signals, the elements AI systems rely on most when deciding whether your content is trustworthy and retrievable. Medium‑priority items often involve accessibility, image context, or supporting metadata that influence certain engines more than others.
This section tells you exactly where to focus your effort first. Fixing the High‑priority items usually results in the fastest and most measurable improvement in your AI Retrieval Index and engine‑specific compatibility scores.
Dimension Breakdown (The Five Core Visibility Signals)

The Dimension Breakdown shows how your page performs across the five foundational signals that determine AI visibility: Structural Integrity, Data Extractability, Entity Clarity, Schema & Metadata, and Freshness & Decay. Each dimension receives a letter grade and a numerical score, along with the specific checks that contributed to that result. These dimensions form the backbone of your AI Retrieval Index.
Understanding these signals helps you diagnose why your page scores the way it does, and where improvements will have the greatest impact on AI retrieval.
Structural Integrity (How Clearly Your Page Communicates Its Structure)
A strong structural foundation ensures AI systems can correctly interpret your hierarchy, intent, and content flow.
What this measures:
- Single, unambiguous H1
- Clean H2/H3 hierarchy
- Logical nesting (H1 → H2 → H3)
- Balanced heading density
- Fragmented intent detection
Why it matters: AI models rely heavily on structural cues to understand topic boundaries, section intent, and content relationships. Clean structure improves interpretability and reduces ambiguity.
Your score example: A (100) – excellent structural clarity.
Data Extractability (How Easily AI Can Parse and Extract Your Content)
Extractability determines whether AI systems can reliably pull information from your page.
What this measures:
- Sufficient word density (300+ words)
- Scrapeable list structures
- Presence of tables or structured data
- Image alt‑text coverage
- Internal link density
Why it matters: AI retrieval depends on clean, machine‑readable content. Lists, tables, and alt text dramatically improve extraction quality.
Your score example: A (100) – fully extractable content.
Entity Clarity (How Well Your Page Defines Its Key Entities)
Entity clarity ensures AI models correctly identify the people, organizations, products, and concepts your page is about.
What this measures:
- Primary entity tokenization
- Article / Content schema
- Author / Person schema
- Organization schema
- Open Graph title alignment
Why it matters: AI systems build semantic graphs from entities. Clear entity signals increase citation probability and topic alignment.
Your score example: B (80) – strong, but with room to improve secondary entity clarity.
Schema & Metadata (Your Machine‑Readable Context Layer)
Schema markup and metadata provide explicit signals that AI systems use to validate meaning, authorship, and structure.
What this measures:
- JSON‑LD schema presence
- Meta description quality
- Canonical URL correctness
- Open Graph tags
- Robots meta compliance
Why it matters: Schema is one of the strongest visibility signals for Perplexity, Gemini, and Google’s Search Graph. Missing or incomplete schema reduces trust and extractability.
Your score example: C (70) – functional but incomplete; high‑leverage improvement area.
Freshness & Decay (How Current and Maintained Your Content Appears)
Freshness signals tell AI systems whether your content is up‑to‑date, maintained, and safe to cite.
What this measures:
- JSON‑LD
dateModified - Machine‑readable timestamps
- Both publish + modified dates
- Evidence of updates since publish
- Content age under 180 days / 12 months
- Update frequency signals
Why it matters: RAG‑driven engines (Perplexity, Gemini) heavily weight freshness. Stale content is less likely to be retrieved or cited.
Your score example: B (85) – strong freshness signals with recent updates.
Engine Compatibility (How Each AI System Interprets Your Page)
The Engine Compatibility section shows how well your page aligns with the retrieval logic of the four major AI systems: Perplexity, OpenAI / ChatGPT, Claude, and Google Gemini. Each engine has its own scoring model, its own interpretation style, and its own visibility requirements. This section reveals how each model “reads” your content, and how likely it is to cite or surface your page in AI‑generated answers.
The overall Engine Compatibility score is an aggregate indicator of cross‑engine visibility strength. The individual engine cards break this down further, showing your citation probability, the engine’s interpretation style, and the specific signals that influence your performance.
Understanding these differences is essential: AI engines do not evaluate content the same way. Optimizing for one does not automatically optimize for the others.
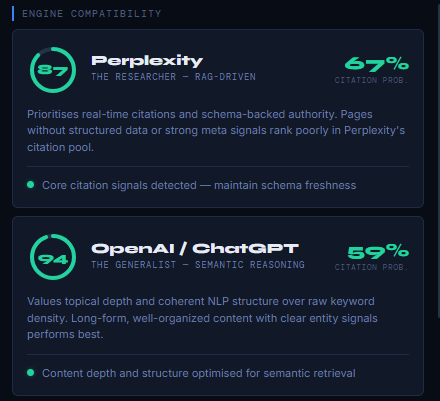
Perplexity – The Researcher (RAG‑Driven)
Why this engine behaves differently: Perplexity relies heavily on real‑time web indexing, RAG retrieval, and schema‑backed authority signals. It prioritizes pages that are easy to cite, verifiable, and structurally explicit.
What it values most:
- Strong JSON‑LD schema
- High‑authority metadata
- Clean, machine‑readable structure
- Verifiable sources
- FAQ and key‑facts structures
Interpretation: Your core citation signals are detected. Maintaining schema freshness and structured data will continue improving Perplexity performance.
OpenAI / ChatGPT – The Generalist (Semantic Reasoning)
Why this engine behaves differently: ChatGPT relies primarily on pre‑trained semantic weights, not live crawling. It rewards topical depth, coherent NLP structure, and clear entity relationships.
What it values most:
- Deep, comprehensive content
- Strong semantic flow
- Clear primary entity definition
- Conversational clarity
- Minimal fluff
Interpretation: Your content depth and structure are optimized for semantic retrieval. This engine responds best to well‑organized, long‑form content.
Claude – The Semanticist (Context & Hierarchy)
Why this engine behaves differently: Claude is extremely sensitive to document hierarchy, contextual consistency, and expertise‑signal identifiers. It penalizes structural disorder more than any other engine.
What it values most:
- Perfect heading hierarchy
- Clear section intent
- Strong authorship signals
- Technical terminology density
- Consistent context
Interpretation: Your hierarchy and authorship signals are well‑optimized. Improving secondary entity clarity can further raise compatibility.
Google Gemini – The Integrator (E‑E‑A‑T & Ecosystem)
Why this engine behaves differently: Gemini integrates Google’s Search Graph with LLM output. It requires strict E‑E‑A‑T, complete Article + Person schema, and strong visual context (alt text, image metadata).
What it values most:
- Article + Person JSON‑LD
- High‑quality alt text
- Clean visual asset context
- E‑E‑A‑T signals
- Canonical + metadata consistency
Interpretation: Your schema is partially complete; adding both Article and Person JSON‑LD types will significantly improve Gemini compatibility. Alt‑text coverage is strong but not perfect; aim for 100%.
Freshness & Decay Model (How AI Evaluates Recency, Maintenance & Content Lifespan)
The Freshness & Decay Model measures how current, maintained, and machine‑verifiable your content appears to modern AI systems. Freshness is not just about publishing new content; it’s about providing clear, machine‑readable signals that your page is actively updated and safe for AI engines to cite.
This section contains two key components: your Content Freshness Score and your Decay Risk Level.
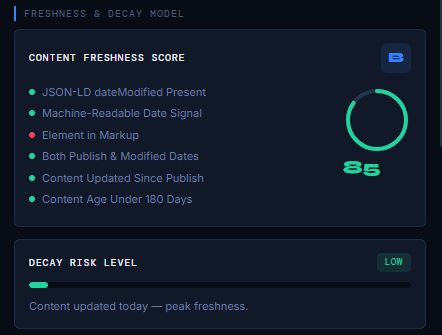
Content Freshness Score (How Recently and Reliably Your Page Was Updated)
The Freshness Score evaluates the explicit signals that AI systems use to determine whether your content is up‑to‑date. These signals are extracted from your schema, metadata, and on‑page timestamps.
What this measures:
- Presence of
dateModifiedin JSON‑LD - Machine‑readable date formats
- Matching publish + modified dates
- Evidence of updates since initial publication
- Content age (typically under 180 days)
- Timestamp consistency across schema, meta, and visible elements
Why it matters: RAG‑driven engines like Perplexity and Gemini rely heavily on freshness to decide whether your page is trustworthy enough to cite. Even if your content is high‑quality, stale or inconsistent timestamps reduce retrieval probability.
Your score example: B (85) – strong freshness signals with recent updates and clean schema.
Decay Risk Level (How Quickly Your Content Is Losing Freshness Value)
Decay Risk indicates how close your content is to becoming “stale” in the eyes of AI systems. It does not measure quality – it measures time‑based trust erosion.
What this reflects:
- How long since the last verified update
- Whether timestamps align across schema, meta, and HTML
- Whether the page shows signs of ongoing maintenance
- How engines interpret your update frequency
Why it matters: Even evergreen content decays over time. Engines like Perplexity and Gemini reduce citation probability as content ages, especially if no updates are detected.
Example: LOW Decay Risk, content was updated today, giving it peak freshness and maximum trust.
Why Freshness & Decay Matter for AI Retrieval
AI systems prefer content that is:
- recent
- maintained
- machine‑verifiable
- schema‑consistent
Freshness is not about rewriting content – it’s about maintaining clear signals that your page is alive, accurate, and safe to cite.
Engine Freshness Sensitivity (How Much Each AI System Cares About Recency)
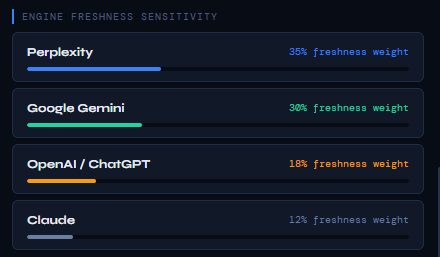
Engine Freshness Sensitivity shows how heavily each AI engine weighs freshness when deciding whether to retrieve, cite, or trust your content. These percentages do not represent your page’s freshness score; they represent the importance of freshness for each engine’s retrieval logic.
Different AI systems rely on different data sources and update cycles. Some engines depend on real‑time web crawling, while others rely primarily on pre‑trained models. As a result, freshness influences each engine’s decision‑making in very different ways.
This section helps you understand why freshness matters more for some engines than others, and where freshness improvements will have the greatest impact.
Perplexity
Perplexity is the most freshness‑sensitive engine because it is RAG‑driven and continuously pulls from live web data. Fresh, schema‑verified timestamps significantly increase citation probability.
Why it cares:
- Real‑time indexing
- Heavy reliance on verifiable metadata
- Preference for recently updated sources
If your content is stale, Perplexity deprioritizes it quickly.
Google Gemini
Gemini integrates Google’s Search Graph, which strongly rewards recency, maintenance, and E‑E‑A‑T signals. Freshness is a major trust factor.
Why it cares:
- Search Graph recency signals
- JSON‑LD timestamp validation
- Update frequency patterns
Gemini expects both the Article and Person schema to confirm freshness.
OpenAI / ChatGPT
ChatGPT relies primarily on pre‑trained semantic weights, not live crawling. Freshness matters, but far less than structure, depth, and entity clarity.
Why it cares (moderately):
- Recency helps with contextual alignment
- Updated schema improves interpretability
- Freshness boosts trust but is not decisive
ChatGPT rewards semantic depth more than recency.
Claude
Claude is the least freshness‑dependent engine. Its retrieval logic prioritizes hierarchy, context, and expertise signals over recency.
Why it cares (lightly):
- Freshness helps, but hierarchy matters more
- Strong authorship and structure outweigh timestamps
- Evergreen content performs well
Claude penalizes structural disorder more than stale timestamps.
Why This Matters
Understanding freshness sensitivity helps you prioritize updates:
- If you want to improve Perplexity or Gemini visibility → focus on freshness, schema timestamps, and update cadence.
- If you want to improve ChatGPT or Claude visibility → focus on depth, structure, and entity clarity first.
Freshness is not equally important across engines – this section shows exactly where it moves the needle.
Query Eligibility (Which Questions Your Content Can Appear For in AI Systems)
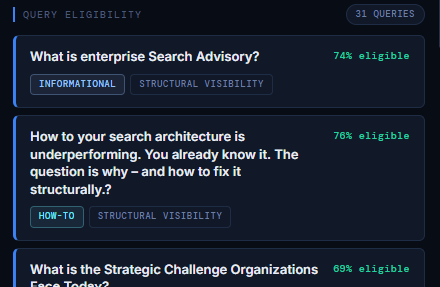
Query Eligibility shows how many real, machine‑interpreted questions your page is eligible to answer inside modern AI systems. Instead of keyword matching, AI engines map your content to questions, intents, and semantic frames. This section reveals which queries your page can satisfy, and how strongly it aligns with each one.
Each eligible query includes:
- the question AI models associate with your content
- the eligibility percentage (how well your page answers it)
- the intent type (Informational, How‑To, Comparative, etc.)
- the semantic category (Structural Visibility, AI, SEO, E‑E‑A‑T, etc.)
This gives you a clear picture of your retrieval footprint – the real surface area where your content can appear in AI‑generated answers.
What Query Eligibility Measures
AI systems evaluate your content against thousands of potential questions and determine:
- Does this page answer the question clearly?
- Is the structure aligned with the intent?
- Are the entities relevant and unambiguous?
- Is the depth sufficient to satisfy the query?
- Is the content extractable and well‑organized?
The eligibility percentage reflects how confidently AI models can use your page as a source for that specific question.
Why Query Eligibility Matters
Query Eligibility is one of the strongest indicators of AI visibility because:
- AI systems retrieve answers, not keywords
- Eligibility determines whether your content is even considered
- Higher eligibility increases citation probability
- It reveals content gaps and missed opportunities
- It shows whether your page aligns with the questions users actually ask
This is the closest equivalent to “keyword coverage” in the AI era – but far more accurate and aligned with how LLMs retrieve information.
How to Interpret Eligibility Percentages
- 80%+ → Strong alignment. Your page is a good candidate for retrieval.
- 70–79% → Solid alignment. Minor improvements can push it into high‑eligibility territory.
- 60–69% → Moderate alignment. The page touches the topic but lacks depth, clarity, or structure.
- Below 60% → Weak alignment. The page is not a reliable answer source for that query.
Our example shows 31 eligible queries, most in the 69–76% range – meaning the page is structurally aligned but could gain stronger eligibility with deeper content or clearer entity signals.
Why Some Queries Appear “Odd”
AI models sometimes generate eligibility for queries that come from:
- navigation elements
- headings
- related posts
- author bios
- contextual mentions
- semantic associations
This is normal – it reflects how AI systems interpret the entire page, not just the main content.
How to Improve Query Eligibility
To increase eligibility across more queries:
- Strengthen definitions and explanations
- Add clear section headers aligned with user intent
- Improve entity clarity (primary + secondary)
- Expand depth where coverage is thin
- Add FAQ sections for common questions
- Improve schema (FAQPage, Article, Person)
- Ensure extractability (lists, tables, alt text)
Small structural improvements often raise eligibility across multiple queries at once.
Entity Graph Stability (How Consistently AI Models Understand Your Topic & Entities)
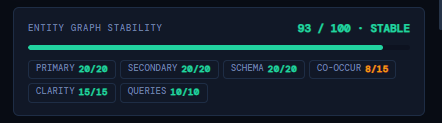
Entity Graph Stability measures how reliably AI systems can interpret the entities on your page – the people, organizations, concepts, products, and relationships that define what your content is about. A stable entity graph means AI models consistently understand your topic, your expertise, and the semantic relationships inside your content.
This is one of the strongest predictors of AI retrieval. If your entity graph is unstable, AI systems hesitate to cite your page – even if the content is high‑quality.
The score is calculated across six sub‑dimensions: Primary Entities, Secondary Entities, Schema, Co‑Occurrence, Clarity, and Query Alignment.
Primary Entities (20/20)
Primary entities are the core concepts your page is fundamentally about. A perfect score means:
- AI models correctly identify your main topic
- The entity is consistently referenced
- The page has a clear semantic anchor
- No competing or ambiguous entities dilute meaning
This is the foundation of a stable entity graph.
Secondary Entities (20/20)
Secondary entities support and contextualize the primary topic. A strong score indicates:
- Supporting concepts are present and relevant
- AI models can map relationships between entities
- The page has sufficient semantic depth
- No missing context that would weaken interpretation
This strengthens topic authority and retrieval confidence.
Schema Signals (20/20)
Schema markup reinforces entity clarity by explicitly defining:
- Article type
- Author / Person
- Organization
- Primary topic
- Relationships between entities
A perfect schema score means your structured data fully supports the entity graph.
Co‑Occurrence Patterns (8/15)
Co‑occurrence measures how often key entities appear together in ways AI models expect. Lower scores here indicate:
- Missing supporting entities
- Inconsistent terminology
- Weak semantic reinforcement
- Gaps in topical coverage
Improving co‑occurrence often boosts both semantic coverage and query eligibility.
Entity Clarity (15/15)
Entity clarity evaluates how unambiguous your entities are. A perfect score means:
- No conflicting terminology
- No ambiguous references
- No unclear pronouns or vague concepts
- Strong, explicit naming conventions
This reduces misinterpretation and increases retrieval accuracy.
Query Alignment (10/10)
Query alignment measures how well your entity graph matches the questions users ask. A perfect score means:
- Your entities align with real informational needs
- AI models can map your content to relevant queries
- Your page is eligible for a wide range of question types
This directly influences your Query Eligibility footprint.
What a 93/100 “STABLE” Score Means
A score of 93 / 100 with a STABLE status indicates:
- AI systems consistently understand your topic
- Your entity relationships are clear and well‑defined
- Schema and metadata reinforce your meaning
- Your content is safe for AI engines to cite
- Only minor improvements (usually co‑occurrence) remain
This is a high‑authority signal – and one of the strongest indicators of long‑term AI visibility.
Detected Entities (How AI Systems Classify the Concepts on Your Page)
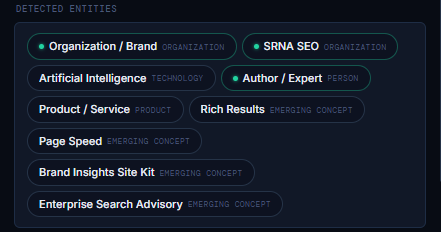
The Detected Entities section shows the organizations, people, technologies, products, and emerging concepts that AI systems extract from your page. These entities form the semantic backbone of how AI models understand your content; they determine your topic, your expertise, and your relevance to specific queries.
AI engines build meaning through entities, not keywords. If the right entities are detected and correctly categorized, your content becomes far easier for AI systems to interpret, retrieve, and cite.
This section reveals exactly which entities your page communicates clearly, and how AI models classify them.
Why Detected Entities Matter
Detected entities influence:
- Entity Graph Stability
- Query Eligibility
- Semantic Coverage
- Engine Compatibility
- Citation Probability
- Topical Authority
If an important entity is missing, misclassified, or ambiguous, AI systems may misunderstand your page’s purpose or fail to retrieve it entirely.
Entity Categories Explained
Each detected entity is assigned a category that reflects how AI models interpret it:
- Organization / Brand – companies, agencies, or branded entities
- Technology – tools, platforms, or technical concepts
- Person – authors, experts, or referenced individuals
- Product / Service – offerings, solutions, or commercial entities
- Emerging Concept – new or evolving ideas, frameworks, or terminology
These categories help AI systems map your content into the correct semantic domain.
What This Example Shows
Your page successfully communicates a mix of:
- Organizational identity (e.g., brand)
- Technical context (AI, search, visibility concepts)
- Authorship and expertise (person as the expert)
- Products and services (advisory, frameworks, tools)
- Emerging concepts (new terminology you’re defining)
This is exactly what a high‑authority page should do: it anchors itself in clear entities while introducing new conceptual territory.
How to Improve Detected Entities
If you want to strengthen entity detection:
- Use consistent naming for key concepts
- Introduce entities early in the content
- Add Article, Person, and Organization schema
- Use clear, unambiguous phrasing
- Reinforce entities through headings and lists
- Add supporting entities that deepen context
Improving entity clarity often boosts Entity Graph Stability, Query Eligibility, and Semantic Coverage simultaneously.
Detected Topics (The High‑Level Themes AI Associates With Your Page)

The Detected Topics section identifies the primary thematic categories that AI systems extract from your content. Unlike entities, which represent specific people, organizations, technologies, or concepts, topics represent broader semantic domains. They tell you how AI models classify your content at the category level.
These topics influence how your page is grouped, compared, and retrieved across AI systems. They also shape which query clusters your content becomes eligible for.
Why Detected Topics Matter
Detected topics help AI systems understand:
- What domain your content belongs to
- Which semantic clusters it should be grouped with
- Which types of questions your page can answer
- How your content relates to other pages in the same topic space
- Whether your expertise aligns with the user’s intent
If the detected topics match your intended positioning, your content is aligned. If they don’t, AI systems may misclassify your page, reducing retrieval accuracy.
How AI Determines Topics
AI models infer topics from:
- heading structure
- repeated terminology
- semantic density
- entity relationships
- contextual cues
- schema markup
- internal linking patterns
Topics are not chosen by frequency alone; they are chosen by semantic weight.
What This Example Shows
Your page is currently associated with topics such as:
- SEO
- Conversion Rate
- Case Studies
This indicates that AI systems interpret your content as:
- part of the SEO domain
- connected to performance and optimization
- supported by practical or analytical examples
This is a strong alignment for content positioned around search visibility, advisory, and strategic frameworks.
How to Improve Topic Detection
If you want AI systems to detect more precise or more strategic topics:
- Strengthen your primary topic signals in headings
- Add supporting secondary topics in sub‑sections
- Use consistent terminology across the page
- Reinforce topics through schema (Article, About, Person, Organization)
- Add contextual examples that anchor the topic
- Ensure internal links point to related thematic content
Improving topic clarity often increases Query Eligibility, Semantic Coverage, and Engine Compatibility simultaneously.
Entity Relationship Map (How AI Models Connect and Interpret Your Entities)
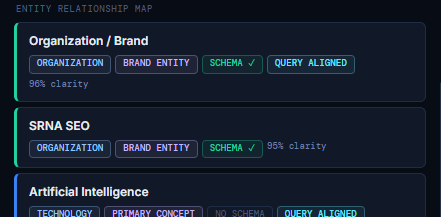
The Entity Relationship Map visualizes how AI systems understand the relationships between the key entities on your page. Unlike the Detected Entities list, which shows what entities are present, the Relationship Map shows how those entities connect, how clearly they are defined, and how strongly they reinforce your topic.
This is the closest representation of the semantic graph that AI engines build internally. A strong, coherent entity graph dramatically increases retrieval confidence, topic authority, and eligibility across a wide range of queries.
Each entity in the map includes:
- Entity Name
- Entity Type (Organization, Person, Technology, Metric, Concept, etc.)
- Semantic Role (Brand Entity, Primary Concept, E‑E‑A‑T Anchor, Proof Element, etc.)
- Schema Status (Schema ✓ or No Schema)
- Query Alignment (how well the entity matches real user questions)
- Clarity Score (how unambiguously the entity is understood)
Together, these signals determine how stable and trustworthy your entity graph is.
How to Read Each Entity Block
Each entity block contains several layers of meaning:
- Entity Type – how AI classifies the entity
- Semantic Role – what function the entity plays in your content
- Schema Status – whether structured data reinforces the entity
- Query Alignment – whether the entity matches real informational needs
- Clarity Score – how confidently AI models interpret the entity
High clarity and strong alignment indicate that AI systems fully understand the entity and its role in your content.
Why This Section Matters
The Entity Relationship Map is one of the strongest predictors of:
- AI Retrieval Index
- Query Eligibility
- Semantic Coverage
- Engine Compatibility
- Citation Probability
If your entity graph is clear, consistent, and schema‑supported, AI systems trust your content more and retrieve it more often.
How to Improve Entity Relationship Strength
To strengthen your entity graph:
- Add or expand schema for key entities
- Reinforce entities through headings and section intros
- Use consistent terminology across the page
- Add supporting entities to deepen context
- Improve co‑occurrence patterns
- Clarify relationships through explicit phrasing
Even small improvements can significantly increase clarity scores and retrieval confidence.
Content Gaps (Missing Entities & Topics That Limit AI Visibility)
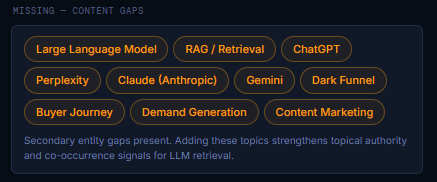
The Content Gaps section highlights the entities, concepts, and topics that AI systems expected to find on your page, but didn’t. These gaps weaken your semantic graph, reduce co‑occurrence strength, and limit your eligibility for high‑value AI queries.
AI engines build meaning through entity networks. If key supporting entities are missing, your content appears:
- less authoritative
- less complete
- less contextually rich
- less aligned with real user questions
This section shows exactly which missing concepts would strengthen your topical authority and improve retrieval probability.
Why Content Gaps Matter
Missing entities weaken:
- Entity Graph Stability
- Semantic Coverage
- Query Eligibility
- Engine Compatibility
- Citation Probability
Even if your primary topic is strong, missing secondary entities makes your content appear incomplete or shallow in the eyes of AI systems.
Adding these concepts, even briefly, can significantly improve:
- co‑occurrence patterns
- semantic density
- topic completeness
- AI retrieval confidence
This is one of the highest‑leverage improvement areas for most pages.
How to Interpret the Missing Topics
Each highlighted topic represents a secondary entity that AI models associate with your domain, but did not detect in your content. These are not random keywords; they are semantic expectations based on your page’s subject matter.
Below is how to interpret the examples shown:
Large Language Model
A foundational concept in AI visibility. Missing this weakens your alignment with AI‑related queries.
RAG / Retrieval
A core mechanism behind Perplexity, Gemini, and modern AI search. Including it strengthens the technical context and retrieval relevance.
ChatGPT, Perplexity, Claude, Gemini
These engines form the ecosystem your content is discussing. Mentioning them increases:
- engine‑specific eligibility
- semantic coverage
- co‑occurrence with AI systems
Dark Funnel
A strategic concept tied to modern visibility and attribution. Its absence reduces alignment with marketing‑adjacent queries.
Buyer Journey
A key concept in advisory, strategy, and conversion‑focused content. Adding it strengthens your cross‑domain semantic footprint.
Demand Generation
A major topic in marketing and visibility frameworks. Its absence signals incomplete topical coverage.
Content Marketing
A foundational concept connected to SEO, visibility, and advisory work. Including it improves semantic completeness.
How to Fix Content Gaps
You don’t need to write long sections about each missing topic. Often, a single sentence or short paragraph is enough to:
- anchor the entity
- reinforce the semantic graph
- improve co‑occurrence
- increase eligibility
- strengthen retrieval signals
Practical ways to add missing entities:
- Add a short contextual mention
- Include them in a comparison or example
- Add them to a FAQ section
- Reference them in a definition or explanation
- Use them in a heading or subheading
- Add them to schema (where appropriate)
Even minimal inclusion can significantly improve your AI visibility footprint.
Author Ivica Srncevic
Enterprise SEO strategist specializing in search architecture and AI-driven visibility. With 25+ years of experience across global organizations including Adecco Group and Atlas Copco, he works on designing, diagnosing, and optimizing how complex digital ecosystems are structured, understood, and surfaced by search engines and AI systems.